此篇是參考 Referenece 1. 的內容,實際操作一次 Delta Live Tables 的 pipeline。
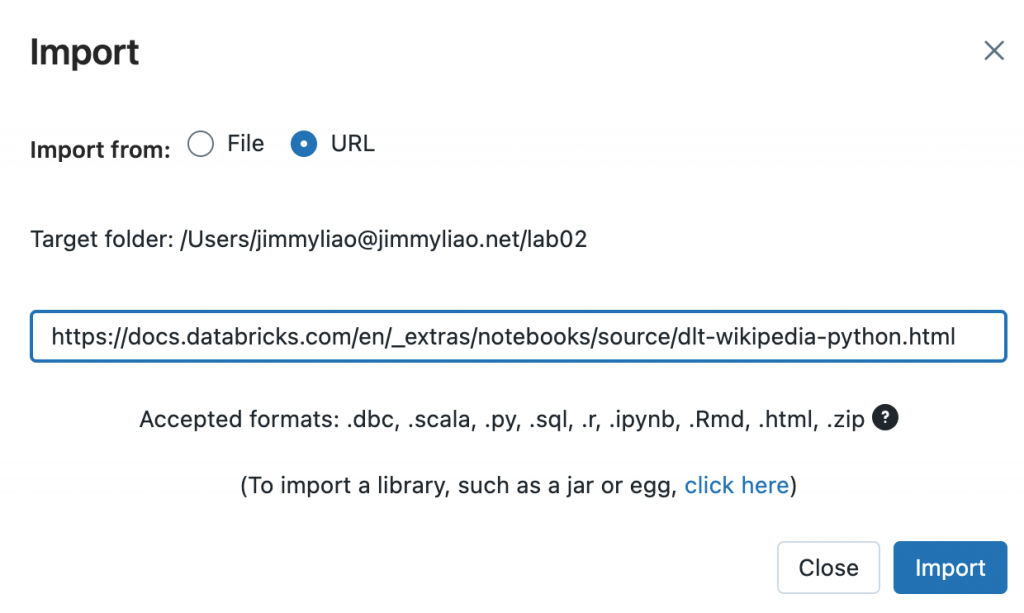
Example Python Notebook 可以從這裡下載。
# Imports
import dlt
from pyspark.sql.functions import *
from pyspark.sql.types import *
# Ingest raw clickstream data
json_path = "/databricks-datasets/wikipedia-datasets/data-001/clickstream/raw-uncompressed-json/2015_2_clickstream.json"
@dlt.create_table(
comment="The raw wikipedia clickstream dataset, ingested from /databricks-datasets."
)
def clickstream_raw():
return (
spark.read.json(json_path)
)
# Clean and prepare data
@dlt.table(
comment="Wikipedia clickstream data cleaned and prepared for analysis."
)
@dlt.expect("valid_current_page_title", "current_page_title IS NOT NULL")
@dlt.expect_or_fail("valid_count", "click_count > 0")
def clickstream_prepared():
return (
dlt.read("clickstream_raw")
.withColumn("click_count", expr("CAST(n AS INT)"))
.withColumnRenamed("curr_title", "current_page_title")
.withColumnRenamed("prev_title", "previous_page_title")
.select("current_page_title", "click_count", "previous_page_title")
)
# Top referring pages
@dlt.table(
comment="A table containing the top pages linking to the Apache Spark page."
)
def top_spark_referrers():
return (
dlt.read("clickstream_prepared")
.filter(expr("current_page_title == 'Apache_Spark'"))
.withColumnRenamed("previous_page_title", "referrer")
.sort(desc("click_count"))
.select("referrer", "click_count")
.limit(10)
)
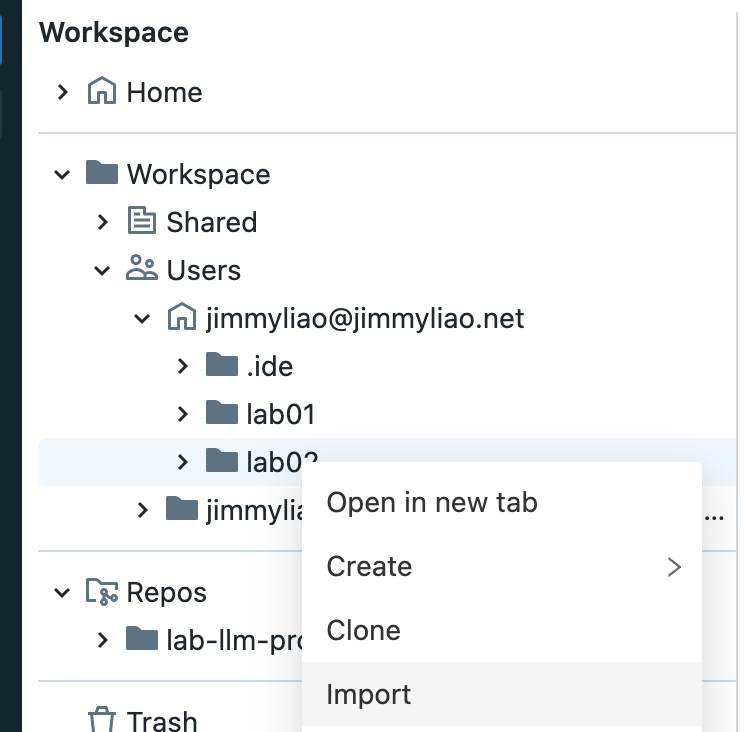
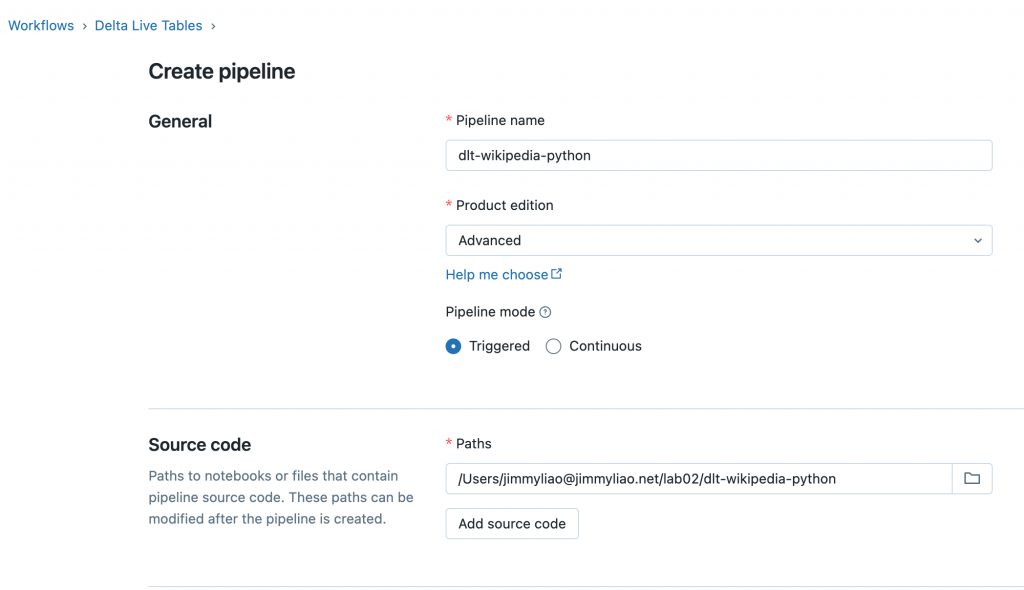
建立一個 pipeline,也就是定義一個 notebook 或是 source code,並且在內容中使用 Delta Live Tables syntax 來定義 dependencies。注意每個 source code 只能是一種程式語言,但是可以在 pipeline 中透過 libraries 混用不同的程式語言。
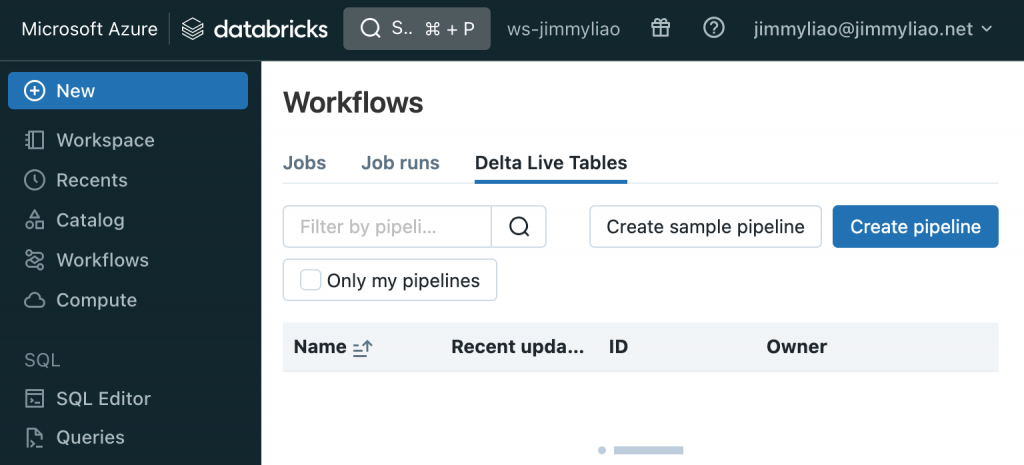
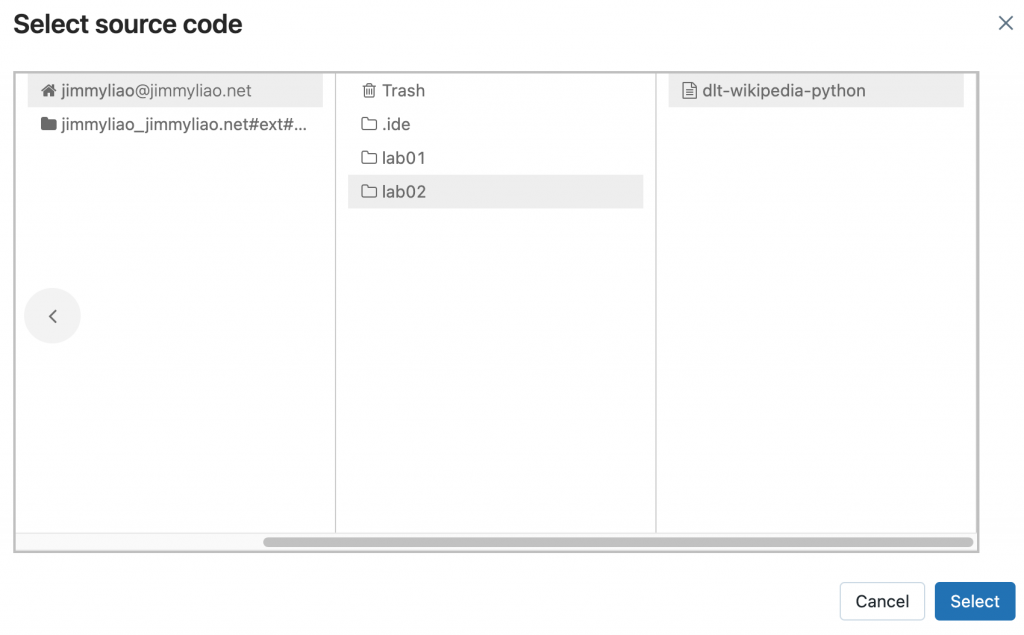
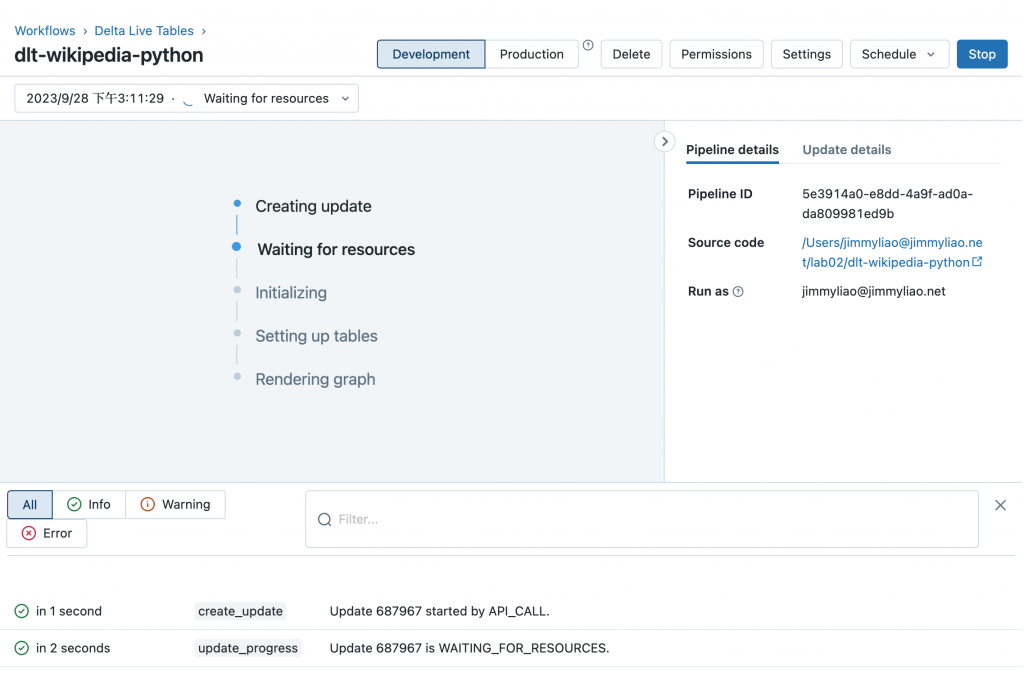
底下為一些步驟的截圖,可以參考。
Reference:


 iThome鐵人賽
iThome鐵人賽